CI/CD data time decay
Summary
GitLab CI/CD, integrated into GitLab in 2015, is a crucial yet resource-intensive component that has experienced exponential growth, surpassing 1 billion builds by 2021.
Despite its evolution, the CI/CD data storage architecture remains largely unchanged since 2012, posing scalability challenges due to the vast volume of data stored in PostgreSQL.
The proposed strategies involves:
- Partitioning CI/CD data tables to efficiently support large scale of data and reduce the risk of databae performance degradation.
- Reducing the growth rate of metadata by being efficient in the data to store at any given stage of the pipeline lifecycle.
- Archiving pipeline data to consistently move less accessed data to other storage solutions like object storage and enforce a different access pattern.
- Introducing configurable data retention policies.
This architectural overhaul aims to enhance reliability, scalability, and performance while maintaining data accessibility and compliance.
Goals
This architectural overhaul aims to enhance reliability, scalability, and performance while maintaining data accessibility and compliance.
Challenges
There are more than two billion rows describing CI/CD builds in GitLab.com's database. This data represents a sizable portion of the whole data stored in PostgreSQL database running on GitLab.com.
This volume contributes to significant performance problems, development challenges and is often related to production incidents.
We also expect a significant growth in the number of builds executed on GitLab.com in the upcoming years.
Opportunity
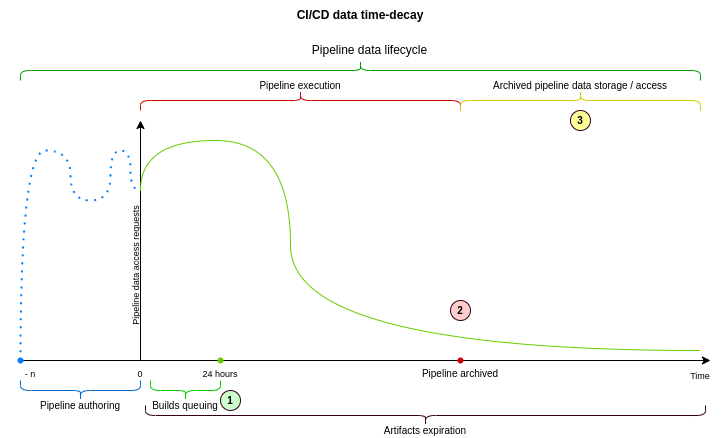
CI/CD data is subject to time-decay because, usually, pipelines that are a few months old are not frequently accessed or are even not relevant anymore. Restricting access to processing pipelines that are older than a few months might help us to move this data out of the primary database, to a different storage, that is more performant and cost effective.
It is already possible to prevent processing builds that have been archived. When a build gets archived it will not be possible to retry it, but we still do keep all the processing metadata in the database, and it consumes resources that are scarce in the primary database.
To improve performance and make it easier to scale CI/CD data storage we might want to follow these three tracks described below.
- Partition CI/CD builds queuing database tables
- Partition CI/CD pipelines database tables
- Reduce the rate of builds metadata table growth
Principles
All the three tracks we will use to implement CI/CD time decay pattern are associated with some challenges. As we progress with the implementation we will need to solve many problems and devise many implementation details to make this successful.
Below, we documented a few foundational principles to make it easier for everyone to understand the vision described in this architectural blueprint.
Removing pipeline data
While it might be tempting to remove old or archived data from our databases this should be avoided. It is usually not desired to permanently remove user data unless consent is given to do so. We can, however, move data to a different data store, like object storage.
Archived data can still be needed sometimes (for example for compliance or auditing reasons). We want to be able to retrieve this data if needed, as long as permanent removal has not been requested or approved by a user.
Accessing pipeline data in the UI
Implementing CI/CD data time-decay through partitioning might be challenging when we still want to make it possible for users to access data stored in many partitions.
We want to retain simplicity of accessing pipeline data in the UI. It will require some backstage changes in how we reference pipeline data from other resources, but we don't want to make it more difficult for users to find their pipelines in the UI.
We may need to add "Archived" tab on the pipelines / builds list pages, but we should be able to avoid additional steps / clicks when someone wants to view pipeline status or builds associated with a merge request or a deployment.
We also may need to disable search in the "Archived" tab on pipelines / builds list pages.
Accessing pipeline data through the API
We accept the possible necessity of building a separate API endpoint / endpoints needed to access pipeline data through the API.
In the new API users might need to provide a time range in which the data has been created to search through their pipelines / builds. To make it efficient it might be necessary to restrict access to querying data residing in more than two partitions at once. We can do that by supporting time ranges spanning the duration that equals to the builds archival policy.
It is possible to still allow users to use the old API to access archived pipelines data, although a user provided partition identifier may be required.
Other strategies considered
Partition CI/CD builds queuing database tables
While working on the CI/CD Scale blueprint, we have introduced a new architecture for queuing CI/CD builds for execution.
This allowed us to significantly improve performance. We still consider the new solution as an intermediate mechanism, needed before we start working on the next iteration. The following iteration that should improve the architecture of builds queuing even more (it might require moving off the PostgreSQL fully or partially).
In the meantime we want to ship another iteration, an intermediate step towards more flexible and reliable solution. We want to partition the new queuing tables, to reduce the impact on the database, to improve reliability and database health.
Partitioning of CI/CD queuing tables does not need to follow the policy defined for builds archival. Instead we should leverage a long-standing policy saying that builds created more 24 hours ago need to be removed from the queue. This business rule is present in the product since the inception of GitLab CI.
Epic: Partition CI/CD builds queuing database tables.
For more technical details about this topic see pipeline data partitioning design.
Iterations
All three tracks can be worked on in parallel:
- Reduce the rate of builds metadata table growth.
- Partition CI/CD pipelines database tables.
- Partition CI/CD queuing tables using list partitioning
Status
In progress.
Timeline
- 2021-01-21: Parent CI Scaling blueprint merge request created.
- 2021-04-26: CI Scaling blueprint approved and merged.
- 2021-09-10: CI/CD data time decay blueprint discussions started.
- 2022-01-07: CI/CD data time decay blueprint merged.
- 2022-02-01: Blueprint updated with new content and links to epics.
- 2022-02-08: Pipeline partitioning PoC merge request started.
- 2022-02-23: Pipeline partitioning PoC successful
- 2022-03-07: A way to attach an existing table as a partition found and proven.
- 2022-03-23: Pipeline partitioning design Google Doc (GitLab internal) started:
https://docs.google.com/document/d/1ARdoTZDy4qLGf6Z1GIHh83-stG_ZLpqsibjKr_OXMgc. - 2022-03-29: Pipeline partitioning PoC concluded.
- 2022-04-15: Partitioned pipeline data associations PoC shipped.
- 2022-04-30: Additional benchmarking started to evaluate impact.
- 2022-06-31: Pipeline partitioning design document merge request merged.
- 2022-09-01: Engineering effort started to implement partitioning.
- 2022-11-01: The fastest growing CI table partitioned:
ci_builds_metadata. - 2023-06-30: The second largest table partitioned:
ci_builds. - 2023-12-12:
ci_buildsandci_builds_metadatagrowth is stopped by writing data to new partitions. - 2024-02-05:
ci_pipeline_variablesis partitioned. - 2024-03-26:
ci_job_artifactsis partitioned. - 2024-04-26:
ci_stagesis partitioned.